-

Бизнес-задачи

Реальные кейсы




DLP-система
20.01.2023
9 мин.
Анализ в DLP: контекст, контент, методы анализа лучших DLP-систем
Чтобы понять, как работают особенности различных методов анализа в современных DLP-системах, следует разобраться в том, каким образом такое программное обеспечение обрабатывает контент и контекст. Одна из самых важных характеристик DLP-систем – их умение «видеть» данные. Они способны анализировать различного рода контент и контекст, в котором существует этот контент.
В статье специалисты аналитического центра Falcongaze SecureTower объясняют, в чем заключается разница между контекстным и контентным анализом DLP-систем, описывают их особенности, а также рассказывают о наиболее популярных методах анализа контента, которые реализованы в современных DLP-системах.
Как работает анализ контента и контекста в DLP
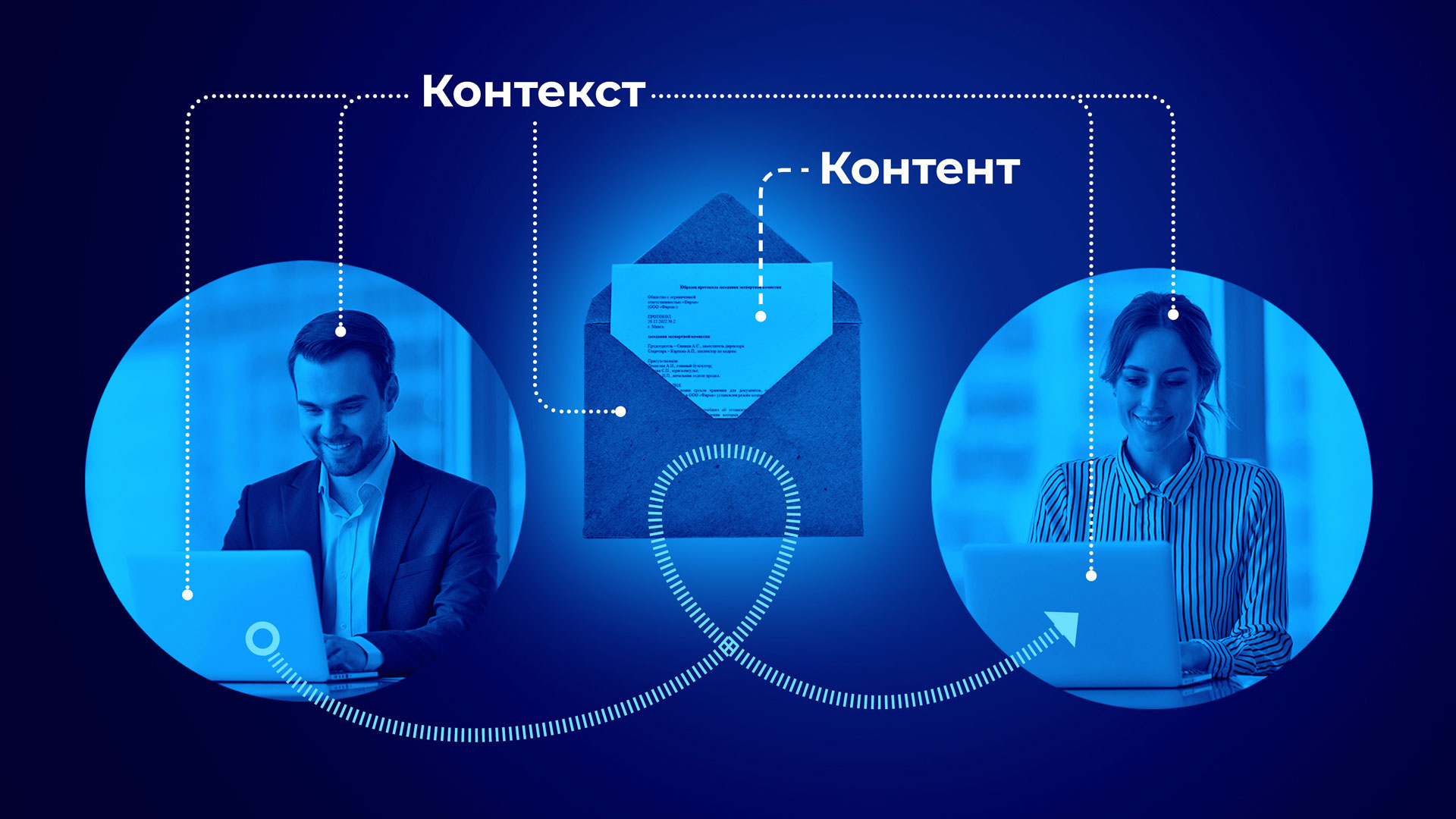
Представим, что контент – это содержание письма, а контекст – это конверт, в котором оно находится, и любые факторы, которые связаны с его окружением. Например, к ним могут быть отнесены источник, место назначения, размер, получатель/и, отправитель, тема, метаданные, время, формат. То есть все, кроме содержания самого письма.
Исходя из практического назначения DLP-системы, она должна уметь анализировать контекст с учетом различных индивидуальных условий среды, в которой существует. То есть контекстуальный анализ в DLP-системах – это уникальная работа с данными, которые каким-либо образом существуют именно в конкретной бизнес-среде, а также анализ присвоенных им атрибутов. Вернёмся к примеру с письмом. Благодаря конверту (то есть контексту, в котором существует контент – содержание письма) мы способны получить информацию минимум о получателе и отправителе. Можно ли это назвать полноценным анализом контекста? Нет. Контекстуальный анализ DLP-системы способен комплексно проанализировать конкретную бизнес-среду: определить инструмент передачи данных, связать эту информацию с отправителем и т.д. Это поможет нам сделать вывод о том, какую степень риска следует присвоить событию, в котором оказался контент, и стоит ли предпринимать какие-либо действия, чтобы защитить его.
Итак, анализ контента – это анализ именно содержания письма. Перед тем, как провести его, нужно совершить ряд дополнительных действий: получить доступ к конверту, открыть его, прочитать, обработать эту информацию, и только потом решить, какие действия предпринять далее – то есть провести анализ контекста.
Сегодня DLP-системе недостаточно иметь лишь навыки контентного анализа. Именно навык анализировать контекст имеет очень большое значение для такого класса программных продуктов, как DLP. Любая современная DLP-система должна обладать способностями проводить детальный контекстуальный анализ. Такая функция должна быть неотъемлемой частью DLP.
Особенности контекстного анализа в DLP-системе
Ещё относительно недавно (по меркам развития технологий) контекстуальный анализ был довольно простым: существенным преимуществом считалось наличие возможности анализа метаданных файлов. Однако сегодня методы контекстуального анализа существенно развились: теперь они способны учитывать и обрабатывать более сложную информацию. К ней относится:
- Информация о создателе файла, разрешениях и правах доступа к файлу.
- Зашифрованные файлы или сетевые протоколы.
- Место пользователя в организации (посредством интеграции служб каталогов, например, Active Directory).
- Информация о приложениях и программах (например, мессенджерах), почтовых сервисах, форумах и сайтах.
- Информация об устройствах USB или других съёмных устройствах, подключаемых к рабочей станции (например, производитель или номер модели).
Именно контекстный анализ часто служит основой для создания политик контент-анализа. Это одно из основных преимуществ анализа в DLP — вместо того, чтобы рассматривать саму конфиденциальную информацию, можно создавать политики, которые будут учитывать все важные атрибуты среды, в которой такая информация существует.
При защите конфиденциальных данных организации нужно обеспечивать их безопасность в любом месте, где бы они оказались, а не только там, где они хранятся. И если конфиденциальные данные по каким-либо причинам покинули своё безопасное место, следует иметь возможность оперативно принять меры по устранению рисков утечки данных, к которой может привести эта ситуация. Это довольно сложно сделать, не обладая комплексным подходом. Поэтому и существуют DLP-системы как класс программных продуктов, которые способны обеспечить такой подход к защите.
Особенности контентного анализа в DLP-системе
Первый шаг при анализе контента – это перехватить его и получить к нему доступ. Затем DLP-системе нужно понять контекст (он нужен для анализа) и исследовать его. Отметим, что при работе с обычными текстовыми файлами это легко решаемая задача. Немного сложнее, когда DLP-системе следует обрабатывать бинарные файлы.
Традиционно DLP-системы решают эту задачу с помощью технологии взлома файлов. Она используется для чтения и «понимания» файла, когда его содержимое скрыто. Российские DLP-системы, представленные сегодня на рынке, способны распознавать содержимое в около 300 различных форматах файлов, в том числе и зашифрованных. Например, это может быть таблица Excel, встроенная в заархивированный документ Word. В таком случае DLP-система должна сначала разархивировать файл, прочитать документ Word и проанализировать его содержимое, а затем найти, прочитать и проанализировать таблицу Excel. Могут быть и более сложные ситуации: например, когда DLP-системе приходится прочитать pdf-файлы, встроенные в САПР-файлы.
Схема «Анализ в DLP-системе»

Анализ в DLP: современные методы анализа контента
После доступа к содержимому используются ряд методов анализа DLP-систем, которые помогают определить нарушения политики безопасности информации в организации. Расскажем подробнее о принципе работы трёх методов анализа, которые реализованы в наиболее современных и высокотехнологичных DLP-системах.
Сигнатуры и DLP-система
Сигнатурный анализ – это самый распространённый метод контроля конфиденциальных данных, который может быть реализован в DLP-системе. Эффективность этого метода зависит от количества и проработанности установленных словарей, в которых включены слова и выражения, появление которых в бизнес-среде требует внимания. Например, в организации, где установлена DLP-система и существует словарь для контроля переписки с контрагентами, при упоминании работниками слов «взятка», «откат» или других подобных слов DLP-система оповестит об этом ответственное лицо.
Если словари «собраны» качественно, например, с учётом транслитерации или использования латинских букв вместо русских, то точность выявления нарушения политики безопасности будет близка к 100%. Кроме этого, при работе этого метода обеспечивается очень низкий уровень ложноположительных срабатываний DLP (их практически нет).
Регулярные выражения (маски) и DLP-система
Анализ с помощью регулярных выражений – это также один из наиболее распространенных методов анализа содержания, реализуемый как в полноценных DLP-системах, так и в других инструментах, которые имеют лишь некоторые функции DLP. С помощью регулярных выражений (также их называют масками) можно проанализировать контент на наличие совпадений, установленных определёнными правилами.
Этот метод анализа удобен при поиске числовых сведений известной формы: банковских, финансовых, юридических, контактных, персональных и других данных. Например, в организации может существовать правило: нельзя сообщать любые номера счетов в переписке с контрагентами по электронной почте. Выявить нарушение помогут именно регулярные выражения (маски).
Большинство DLP-систем имеют большое количество предустановленных наборов правил, что помогает быстро внедрить систему. Кроме этого, при необходимости у организации будет возможность быстро создать уникальные и персонализированные правила. Это позволит определять тот контент, который ей свойственен, благодаря чему можно свести к минимуму количество ложноположительных срабатываний.
Хеш-функции (цифровые отпечатки) и DLP-система
Анализ с использованием цифровых отпечатков – это один из самых новых методов анализа содержания в DLP-системах. Объясним принцип его работы. Сначала с конфиденциальных данных следует «снять отпечатки»: выявить чувствительное содержание, снять хэши всего корпуса данных и их определённых частей. Затем следует разместить полученные результаты в определённую базу. Данные, которые существуют в бизнес-среде, будут сравниваться именно с этой базой на предмет соответствия. При грамотном вычленении «отпечатков» DLP-система будет довольно точно определять нарушение конфиденциальности данных.
Особенно удобно использовать этот метод, если в организации работают с большим количеством баз данных, чертежей или других видов файлов с нетекстовым содержанием.

Методы анализа и DLP-системы
Помимо упомянутых методов контентного анализа DLP, также существуют лингвистические и статистические методы, которые на сегодняшний день реализованы в любых DLP-системах. Рассмотренные нами методы анализа контента свойственны наиболее развитым и качественным DLP. Так, на российском рынке примером такого программного продукта является DLP-система Falcongaze SecureTower.
В Falcongaze SecureTower реализованы все указанные методы анализа. Кроме этого, она также предоставляет пользователям возможность строить сложные правила анализа контента и контекста, которые сочетают сразу несколько методов, учитывают их последовательность при обработке данных и т.д. Всё это позволяет персонализировать DLP для наиболее продуктивной работы, а с учётом других преимуществ характеризует Falcongaze SecureTower как один из самых выгодных инструментов для защиты данных организации.


 (1).jpg)



.jpg)