Administrator qoʻllanmasi
Средство распознавания ABBYY

Для выполнения процедур распознавания изображений в система SecureTower предусмотрена возможность интеграции с ABBYY FineReader.
Если ваша версия лицензии SecureTower включает ABBYY FineReader, для использования и настройки средства:
- В окне вкладки Основная информация выберите опцию ABBYY.
- Нажмите кнопку Настроить плагин. Окно Средство распознавания содержит группы настроек различных функций средства, необходимых для калибровки средства и доступных на соответствующих вкладках.
- Если требуется восстановить настройки до настроек по умолчанию, нажмите кнопку Использовать базовые настройки, расположенную в нижнем левом углу окна Средство распознавания.
- По окончании всех настроек нажмите OK для сохранения изменений.
Основные настройки
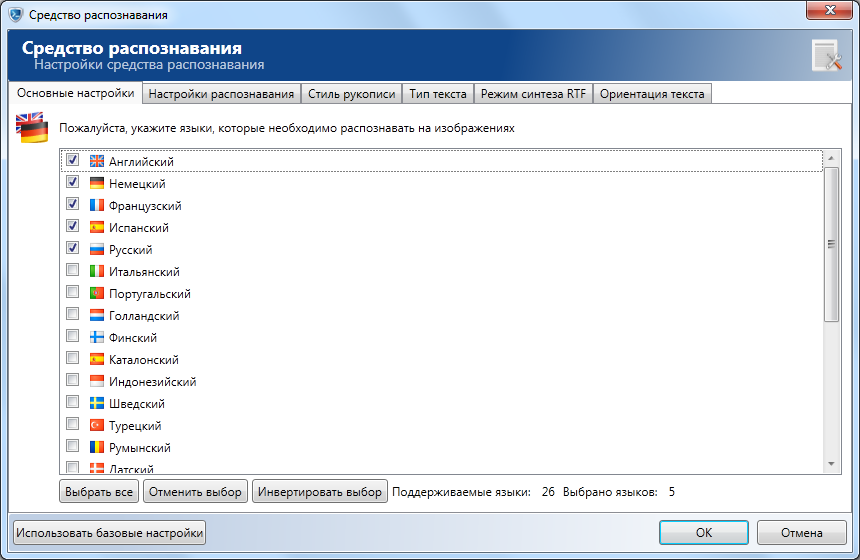
Для выбора языков, которые необходимо распознать, отметьте язык в списке. Используйте полосу прокрутки для просмотра всех языков, доступных для выбора. Для операций выбора также служат кнопки, расположенные под окном просмотра:
- Нажмите кнопку Выбрать все для того, чтобы выбрать для распознавания все языки, отображенные в зоне просмотра.
- Нажмите кнопку Отменить выбор для того, чтобы отменить выбор языков, сделанный ранее.
- Нажмите кнопку Инвертировать выбор для того, чтобы отменить выбор языков, сделанный ранее и, вместе с тем, отметить как выбранные все остальные языки.
Под зоной просмотра языков расположена информационная панель с данными об общем количестве поддерживаемых и числе выбранных пользователем для распознавания языков. Английский язык выбран по умолчанию.
Настройки распознавания
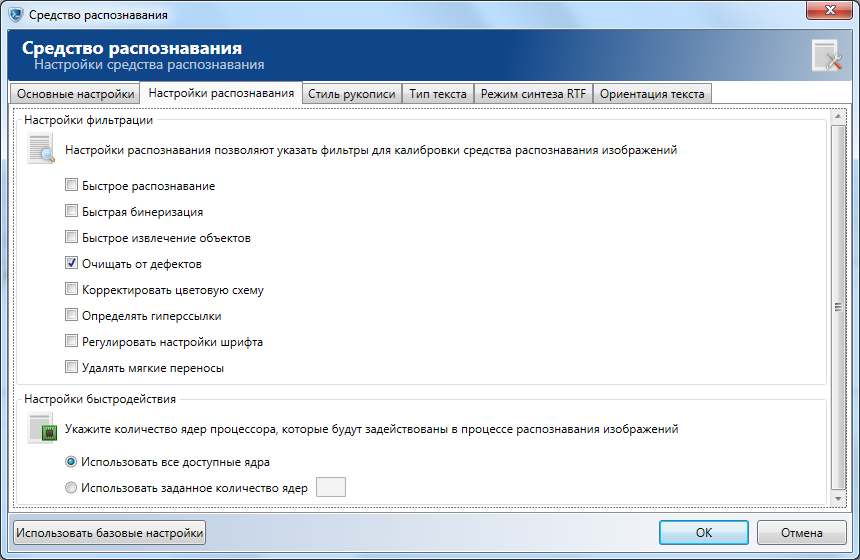
В разделе Настройки фильтрации укажите нужные фильтры:
- Быстрое распознавание - обеспечивает увеличение скорости распознавания в 1,5-2 раза за счет умеренного увеличения погрешности результатов (в 1,5 - 2 раза больше ошибок). Не рекомендуется использовать при распознавании небольших фрагментов, так как прирост в скорости будет незначителен.
- Быстрая бинаризация - ABBYY FineReader будет применять алгоритм быстрой бинаризации, при этом возможно снижение качества результатов.
- Быстрое извлечение объектов - в ходе извлечения определяются побочные объекты (такие как шумы, фоновые рисунки, области низкого качества изображения и т.п.) на изображении. Если эта опция выбрана, то повышается скорость извлечения объектов за счет снижения качества.
- Очищать от дефектов - позволяет очистить изображение от различного рода дефектов. Фильтрация дефектов выполняется для удаления паразитного мусора. Применение фильтра может привести к удалению мелких деталей изображения.
- Корректировать цветовую схему - преобразовывает изображение в черно-белый формат, при этом фон заменяется на белый, а текст на черный или наоборот. При этом возрастает качество изображения, но снижается скорость распознавания.
- Определять гиперссылки - позволяет распознавать гиперссылки на изображении.
- Регулировать настройки шрифта - при выборе данной опции набор шрифтов, используемых при синтезе текстового документа, дополняется расширенными шрифтами в тех случаях, когда в распознаваемом тексте содержатся символы, принадлежащие к шрифтам со сложной структурой.
- Удалять мягкие переносы - указывает ABBYY FineReader удалять мягкие переносы при экспорте распознанного текста в текстовый файл.
В разделе Настройки быстродействия настройте степень быстродействия процесса распознавания. Для этого выберите один из предложенных вариантов работы процессора:
- Все доступные ядра - использование всех ядер процессора, которые доступны, во время распознавания перехваченных изображений позволяет достичь максимально возможного быстродействия сервера распознавания.
- Заданное количество ядер - использование фиксированного количества ядер позволяет рационально распределить нагрузку на физический сервер, на котором установлен сервер распознавания изображений. При этом, если число ядер, указанное в поле ввода, превышает реальное число ядер сервера, в процессе распознавания будет использовано максимальное доступное число ядер процессора.
Настройки распознавания рукописных текстов
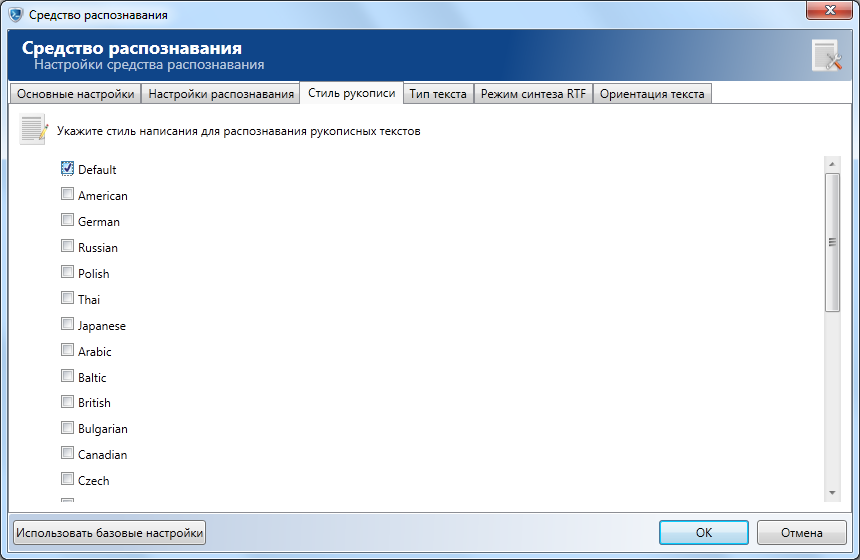
Выберите один или несколько языковых стилей, к которым предположительно относится фрагмент рукописного текста, присутствующий на распознаваемом изображении.
Тип текста
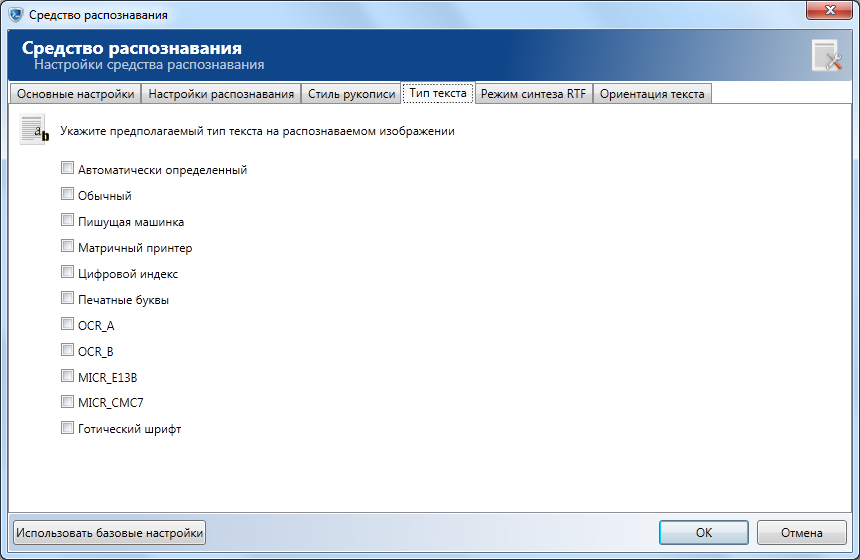
- Автоматически определенный - тип текста будет определен автоматически при выполнении распознавания.
- Пишущая машинка - указывает на то, что текст, представленный на изображении, предположительно был набран на печатной машинке.
- Матричный принтер - указывает на то, что текст, представленный на изображении, предположительно был напечатан на матричном принтере.
- Цифровой индекс - предполагаемый тип текста содержит только цифры, написанные в стиле ZIP-кода.
- Печатные буквы - предполагаемый тип текста соответствует написанным от руки печатным буквами.
- OCR_A - указывает на использование моноширинного шрифта в котором все знаки имеют одинаковую ширину, часто употребляется в банковской сфере и сфере выдачи кредитных карт.
- OCR_B - стиль текста, предназначенный специально для оптического распознавания символов.
- MICR_E13B - стиль, соответствующий использованию определенного набора символов, включающего только цифры и буквы A,B,C,D, напечатанные магнитными чернилами (например, на персональных чеках).
- MICR_CMC7 - стиль, соответствующий использованию определенного набора символов, включающего только цифры и буквы A,B.C,D,E, вписанные в штрих-код.
- Готический шрифт - шрифт текста соответствует готическому стилю написания букв.
Режим синтеза RTF
Для преобразования распознанного текста в RTF - формат необходимо задать режим экспорта.
Выберите один из предложенных режимов:
- Не установлен - способ синтеза распознанного файла не задан.
- Только текст - текст в выходном файле передается в виде одной колонки. Табличное представление не поддерживается. Абзацы сохраняются, в то время как типы и размеры шрифтов не сохраняются.
- Формат абзаца - стиль абзаца и шрифта сохраняется. Форматирование текста внутри абзаца не сохраняется.
- Формат абзаца с поддержкой структуры - сохранение форматирования текста внутри абзацев, включая границы .
- Формат исходного - полное сохранения формата исходного документа, с учетом границ, абзацев и слоев текста. Применяется при распознавании сложных документов, например, рекламных буклетов.
- Редактируемый формат исходного - сохранения формата исходного документа с возможностью редактирования.
Определение ориентации текста на изображении
Если ориентация текстового фрагмента на странице отличается от нормальной, то система определит верную ориентацию при распознавании.
Выберите один из режимов определения ориентации текста на распознаваемом изображении:
- Быстрый - режим обеспечивает самую высокую скорость обнаружения ориентации за счет умеренного снижения качества. Не рекомендуется при типе текста Печатные буквы.
- Стандартный - режим является промежуточным между быстрым и режимом повышенной точности.
- Повышенной точности - режим обеспечивает наилучшее качество определения ориентации текста.