Guía del administrador
Распознавание речи
Система SecureTower позволяет осуществлять анализ данных, переданных в виде голосовых сообщений в программах Microsoft Lync, SIP, Skype, Viber. При перехвате голосовых сообщений система выполнит распознавание, анализ текстовой составляющей и применит к перехваченным данным политики безопасности, установленные в Консоли пользователя.
По умолчанию Сервер распознавания речи SecureTower использует встроенное средство распознавания Sphinx. Вы также можете использовать Wit.ai или Yandex SpeechKit, при наличии их лицензий. Для повышения эффективности распознавания рекомендуется выполнить дополнительную конфигурацию настроек выбранного средства распознавания.
Для того, чтобы настроить параметры распознавания, на боковой панели меню главного окна программы выберите вкладку Распознавание речи.
Внимание!
По умолчанию распознавание речи отключено в настройках Центрального сервера. Для активации распознавания отметьте соответствующую опцию на вкладке Распознавание в окне управления Центральным сервером.
Расширенные настройки сервера
Для изменения расширенных настроек Сервера распознавания речи, установленных по умолчанию:
- В блоке Средство распознавания речи нажмите кнопку Расширенные настройки.
- В открывшемся окне Расширенные настройки установите следующие параметры:
- В блоке Настройки интерфейса введите адрес и порт, прослушиваемые Сервером распознавания речи для взаимодействия с другими компонентами системы.
- Для передачи данных по зашифрованному каналу отметьте опцию Использовать SSL-шифрование. Если установленный по умолчанию SSL-порт 20013 уже используется, укажите порт, который будет использоваться для установления защищенного соединения.
- В блоке Настройки распознавания:
- В поле Максимальный объем документов в очереди (МБ) установите предельный объем, при достижении которого Сервер распознавания перестанет принимать новые данные. Данные будут оставаться на Центральном сервере до освобождения очереди.
- В поле Максимальное количество документов в очереди установите предельное количество, при достижении которого Сервер распознавания перестанет принимать новые данные. Данные будут оставаться на Центральном сервере до освобождения очереди.
- Задайте число потоков для обработки очереди, учитывая возможности системы. Увеличение числа потоков повышает скорость распознавания, но, если число потоков превышает возможности системы, скорость распознавания снижается.
- В блоке Настройки распознавания документа:
- В поле Максимальное время распознавания (сек) введите время, по истечении которого сервер остановит распознавание документа. Информация о прекращении распознавания будет отправлена Центральному серверу. Документ будет считаться нераспознанным, помещен в базу данных в оригинальном формате. В результатах поиска такой документ будет отображаться как аудиофайл.
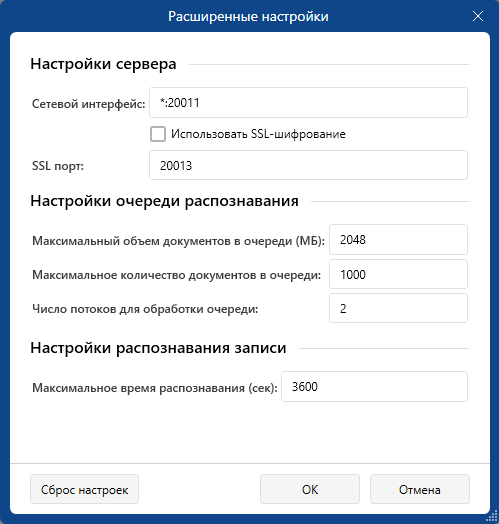
Для возврата к настройкам по умолчанию нажмите Сброс настроек.